
15K Documents
Format-Aware · Hierarchical Indexing
Format-Aware Parsing
Content-Type Indexing
pymupdf4llm · Docling · Textract
Recursive · Hierarchical Chunking
RAPTOR · Late Chunking
Hybrid Search · BM25 + Vector + RRF
Amazon Bedrock · Titan V2
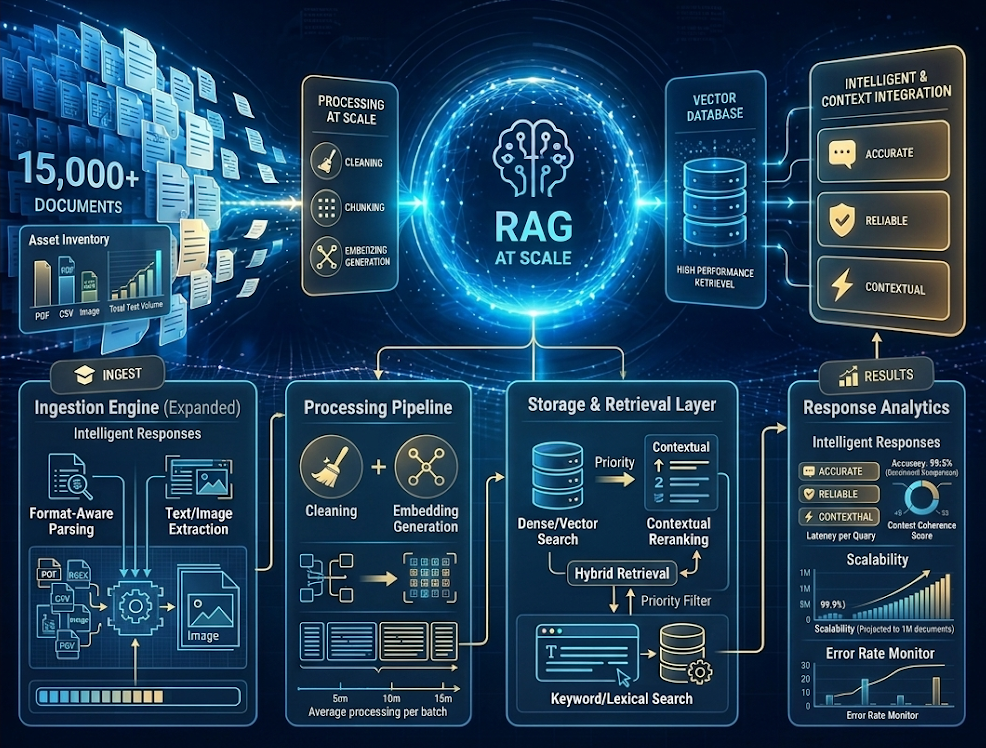
Technical Blueprint Summary
10+
Document formats in a typical enterprise corpus
~50
Chunks per document at 512-token default chunk size
20%
Retrieval drop from embedding raw JSON without flattening
45%
Accuracy drop from embedding tables without the multi-vector pattern
// P3Fusion RAG Ingestion Pipeline · Event-Driven · Fully Parallelised20 concurrent ECS workers
S3 Upload
Event notification → SQS
→
Detect Format
MIME + magic bytes
→
Parse
Format-specific parser
→
Classify Content
Text · Table · Image · Code
→
Chunk
Content-type-aware
→
Embed
Titan V2 · Bedrock
→
Index
Vector + keyword written
// Document Parser Routing · Dispatched per document, not per deploymentFormat detected via MIME + magic bytes
PDF (digital): pymupdf4llm → pdfplumber. Highest accuracy and structure preservation; pdfplumber fallback for complex multi-column tables.
PDF (scanned): Amazon Textract → Tesseract. Stronger OCR and table extraction for noisy scans and handwriting.
DOCX: Docling (IBM) → python-docx. Preserves hierarchy, sections, tables, and reading order.
XLSX: openpyxl → SQL Agent path. Rows are linearised into natural language; raw table embedding is avoided.
PPTX: python-pptx + VLM for visuals. One slide equals one chunk with notes and visual captions.
HTML: Trafilatura → BeautifulSoup. Boilerplate removed; JS-heavy pages rendered via Playwright first.
EML/MSG: Unstructured partition_email(). Recursive attachment parsing and thread reconstruction.
JSON/XML: custom flattener → Docling XML. Structural tokens are removed before embedding to avoid ~20% retrieval degradation.
Prose Text
Recursive split at 512 tokens with 15% overlap, respecting heading boundaries.
Tables
Multi-vector pattern: summary embedding for retrieval, raw table preserved for generation.
Images & Diagrams
Layout detection filters decorative elements; informational visuals are VLM-captioned.
Charts & Graphs
DePlot converts charts to markdown tables, then trends are summarised and indexed.
Code Blocks
Tree-sitter AST chunking by function and class boundaries; generated/vendor code excluded.
Math Formulas
VLM extraction to LaTeX plus natural-language descriptions for exact and conceptual lookups.
"Hierarchical parent-child chunking is where you go next, not where you start. Index 512-token children for precise retrieval. Return 2,048-token parents to the LLM for context."
— P3Fusion Engineering, InsightBot Chunking Architecture
1
RAPTOR — Recursive Hierarchical Tree Indexing
+20% QuALITY benchmark accuracy
2
Late Chunking — Full Document Context Preserved in Every Chunk
+24.5% nDCG@10 vs naive chunking
3
Proposition Indexing — Atomic Factual Statements
High information density for legal and financial corpora
4
Two-Stage Retrieval with Cross-Encoder Reranking
+15–30% accuracy with no re-indexing required
"Reranking is the upgrade we recommend to every client after their first deployment stabilises. It changes selection quality without changing indexing infrastructure."
— P3Fusion Engineering, InsightBot Production Optimisation
P3Fusion
AWS Generative AI Competency Partner. P3Fusion builds enterprise RAG systems — InsightBot for unstructured documents, FusionReport for structured databases, and custom RAG for any corpus. Every deployment uses format-aware ingestion and content-type-specific indexing from day one.
Gen AI Competency
Connect SDP
InsightBot
FusionReport
Custom RAG
Discuss your enterprise RAG ingestion architecture and scaling plan with our engineering team.







